
Optimizing LLM Inference with NVIDIA Run:ai Model Streamer: Reducing Cold Start Latency
ByAinvest
Tuesday, Sep 16, 2025 2:05 pm ET1min read
NVDA--
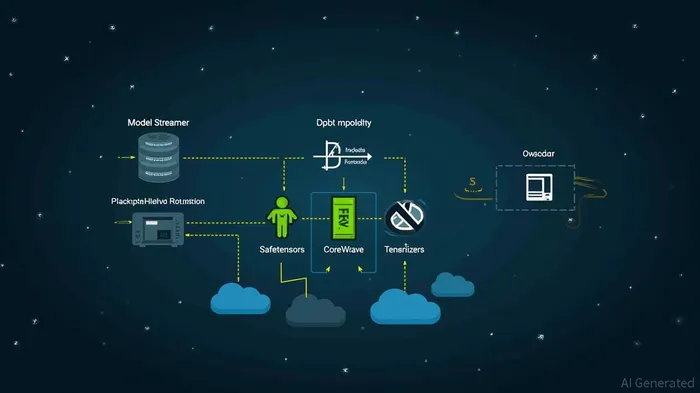
NVIDIA's Run:ai Model Streamer reduces LLM inference cold start latency by concurrently streaming model weights from storage into GPU memory. Benchmarked against Hugging Face's Safetensors Loader and CoreWeave Tensorizer, the Model Streamer significantly lowers model loading times, even in cloud environments. It remains compatible with the Safetensor format and optimizes inference performance by saturating storage throughput and accelerating time-to-inference.
Stay ahead of the market.
Get curated U.S. market news, insights and key dates delivered to your inbox.


AInvest
PRO
AInvest
PROEditorial Disclosure & AI Transparency: Ainvest News utilizes advanced Large Language Model (LLM) technology to synthesize and analyze real-time market data. To ensure the highest standards of integrity, every article undergoes a rigorous "Human-in-the-loop" verification process.
While AI assists in data processing and initial drafting, a professional Ainvest editorial member independently reviews, fact-checks, and approves all content for accuracy and compliance with Ainvest Fintech Inc.’s editorial standards. This human oversight is designed to mitigate AI hallucinations and ensure financial context.
Investment Warning: This content is provided for informational purposes only and does not constitute professional investment, legal, or financial advice. Markets involve inherent risks. Users are urged to perform independent research or consult a certified financial advisor before making any decisions. Ainvest Fintech Inc. disclaims all liability for actions taken based on this information. Found an error?Report an Issue

ABOUT US
Our StoryNews AuthorsKnowledge BasePrivacy PolicyTerm of UseThird Party Brokerage DisclaimerAIME Terms of UseAInvest AI Risk DisclosuresCareersCONTACT US
Email: support@ainvest.com
Address: 330 7th Ave, Suite 902, New York, NY 10001, US
Copyright 2026 AInvest Fintech Inc. All rights reserved.
Comments
No comments yet